
 当前位置:
当前位置:




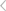

成果简介
先进的电池技术需要精确预测多个组件之间的热化学反应,以有效地利用储存的能量并进行热管理。最近,机器学习(ML)有望解决这一复杂的热化学预测任务。然而,由于问题的高复杂性和可用于模型训练的实验数据极其有限,导致ML仍难以预测电池的热化学行为。
清华大学冯旭宁副教授、张强教授、欧阳明高院士等人创新并验证了温度挖掘(TE)方法,该方法可以在最小的实验中,将热化学反应的动力学偏好解释为数百万个训练数据。在TE方法的帮助下,作者建立了第一个普遍适用的电池热失控模型,该模型在500℃范围内对15种不同的商业和先进化学物质具有不同的电池格式实现了很高的预测精度,并涵盖了所有正常工作条件。TE方法在各种ML算法上也表现出广泛的适应性和训练稳定性,为ML在热化学和所有热相关研究中开辟了新的跨学科机会。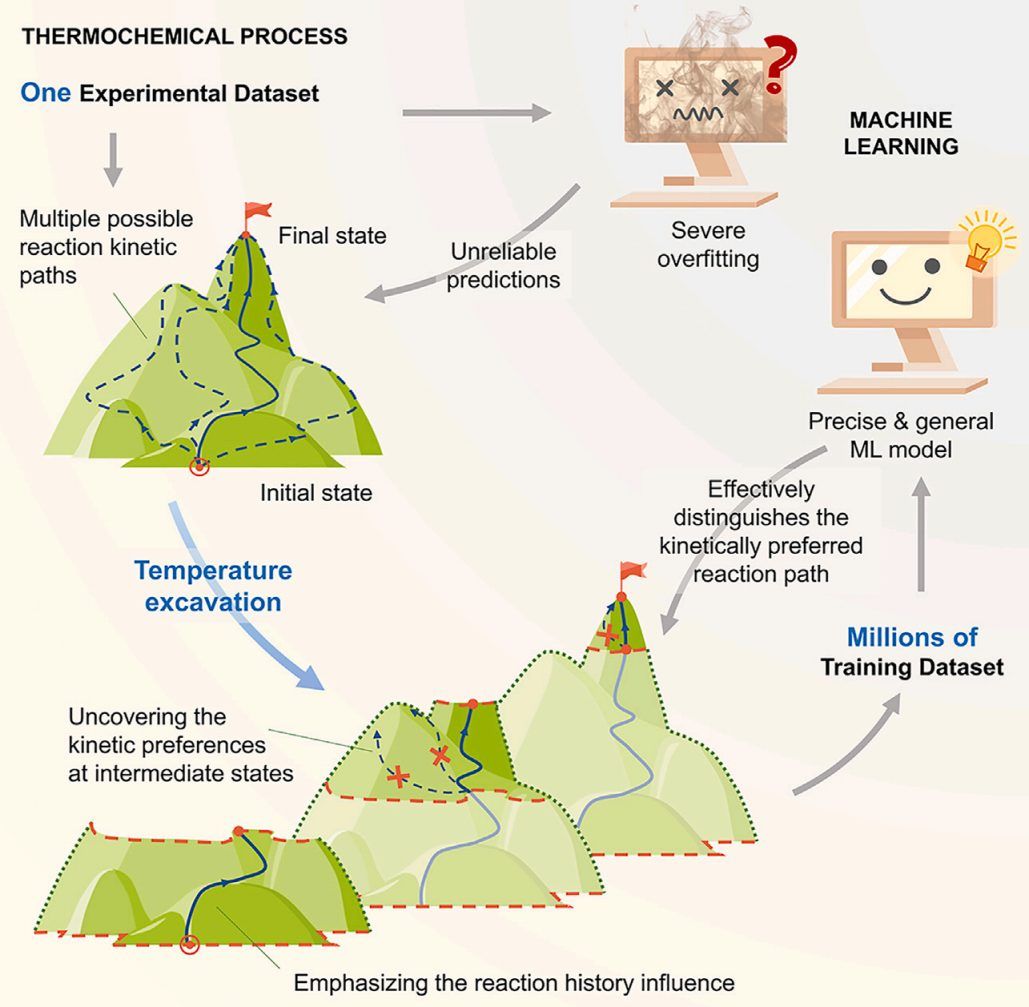 相关工作以《Temperature excavation to boost machine learning battery thermochemical predictions》为题在《Joule》上发表论文。
相关工作以《Temperature excavation to boost machine learning battery thermochemical predictions》为题在《Joule》上发表论文。
图文导读
目前,热化学中的每个实验结果都被数字化为ML的单个训练数据集,这将训练数据的规模与实验量固有地联系在一起(图1A)。
ML模型作为一个数字实体,通过对训练数据的顺序处理来获取知识。训练不足通常会导致拟合结果较差,其中ML模型无法识别和优化变量之间的关系,导致不稳定性和不准确性。一个有104个参数的模型需要4×106个训练样本才能避免严重的过拟合。然而,在大多数前沿电池研究中,没有现有的数据库可以满足这一规模要求。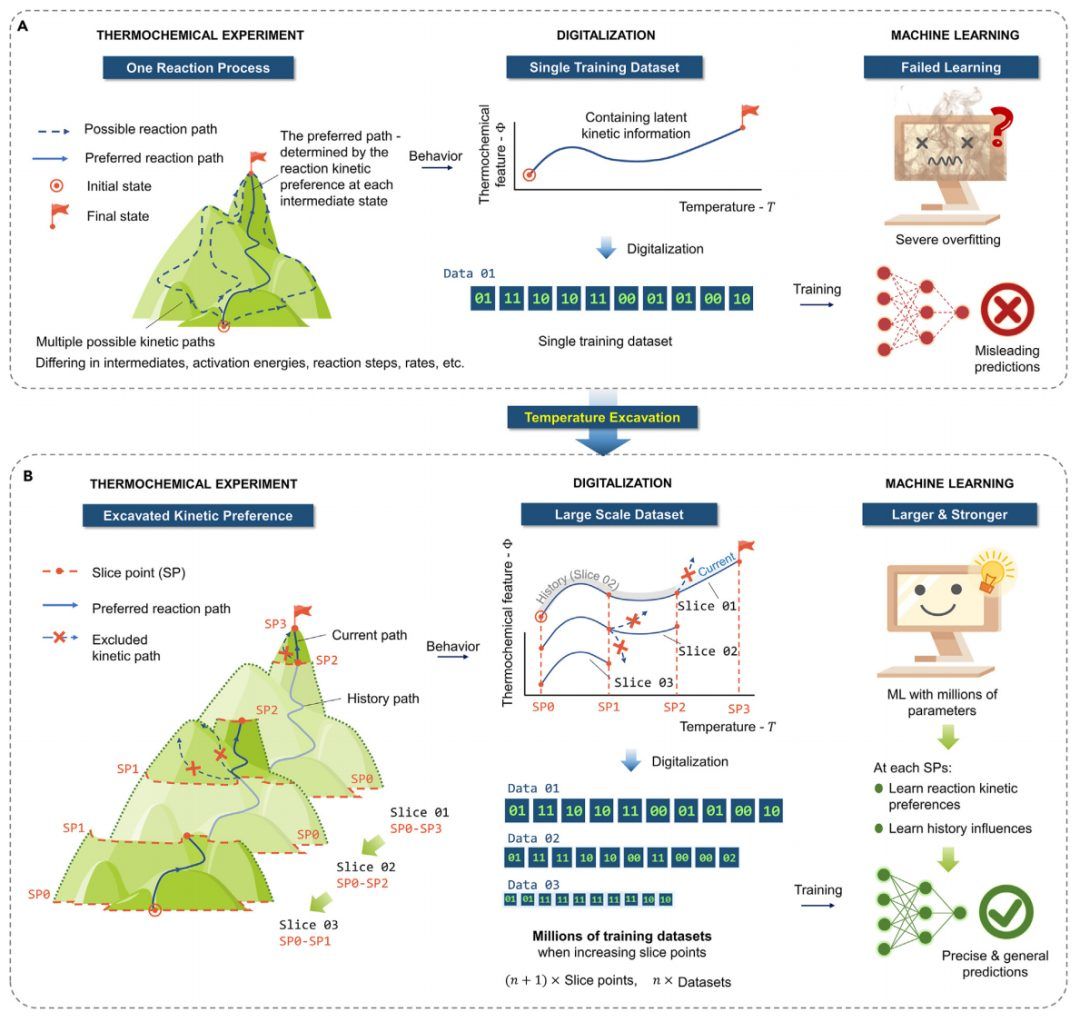 图1 基于温度挖掘的ML精确预测电池热化学反应
图1 基于温度挖掘的ML精确预测电池热化学反应
从热化学的角度来看,每一个热化学过程的热行为都是一个从初始化学状态到最终状态的动力学反应路径的结果(图1A)。一般来说,有几种不同的中间产物、活化能、浓度、反应步骤和反应速率的反应途径可以导致最终状态。然而,在热化学过程中的每个中间点,由于温度、压力、中间体和浓度的变化,反应倾向于采取一条途径而不是其他途径最终达到最终状态(通常是活化能最低的“最简单”途径)。这个过程类似于爬山。在特定条件下选择特定的最优反应路径被称为热化学过程的“动力学偏好”。因此,“动力学偏好”决定了从初始状态到最终状态的首选反应路径,从而产生实验热特征曲线。
随着反应复杂性的增加(例如,当涉及更多的反应物时),可能的反应路径的数量迅速增加。因此,尽管热特征曲线包含了丰富的优先动力学路径信息,但通过观察整体特征曲线来区分优选动力学路径是极其困难的。此外,从机器学习的角度来看,机器学习模型通过逐个处理训练数据集,提取相似性和差异性,学习模式来改进。使用单一的训练数据集可能会导致学习过程失败,存在严重的过拟合问题,并产生误导性的预测(图1A)。因此,关键问题是如何有效地挖掘隐藏在热化学实验中的动力学信息,并将这些知识解释为可以被ML模型学习和理解的大规模训练数据集。
作者提出用温度挖掘(TE)方法来探讨热化学过程中不同中间态的反应动力学偏好。如图1B所示,TE方法首先在整个反应过程中选择几个切点(SPs)(代表不同的中间状态)。图1B以四个SP(SP0~SP3)为例进行说明。然后,从第一个SP(SP0)到其他SP(SP1、SP2和SP3)生成三个TE扩展数据片。
通过比较不同的TE膨胀片,可以得到优选的动力学路径。例如,在SP2,通过对比01片和02片,可以确定热化学特征的发展方向,它反映了特定中间状态下的首选反应路径,从而能够排除不可能的动力学路径。此外,历史反应过程显著影响随后的动力学偏好。在SP2处,02片代表01片的历史段,它直接影响到通向SP3的后续路径。因此,TE方法可以揭示每个SP处历史反应路径的影响。
通过增加SP数并将这些TE扩展的切片数字化,可以实现实验数据规模的大幅增加,有可能在数字领域生成数百万个训练数据集。 图2 温度挖掘方法的应用程序
图2 温度挖掘方法的应用程序
温度挖掘(TE)方法的目的是在ML模型的训练和微调过程中实现实验数据规模的大幅增加。图2说明了采用TE方法开发预测热化学ML模型的整个过程。最初的步骤包括识别预测输入和目标特征。通常,输入包括一个多维矩阵,其中包含可能影响目标的各种特征(图2A演示了一个5维场景)。随后进行热实验,建立输入与目标沿温度轴的相关性(图2B)。这些热实验在高温分辨率下进行,以获得更细的切片和更大的数据扩展比。然后,应用TE方法通过沿温度轴切片、重复和重采样来增加输入-目标数据规模,从而生成n倍扩展的ML训练数据(图2C)。
然后,进一步构建并训练ML模型,该模型的参数尺度现在受到TE扩展数据尺度的限制,而不是实验尺度的限制(图2D)。用于构造机器学习结构的ML算法有很多种,包括ANN、CNN、RNN和transformer。
经过训练的机器学习模型可以进一步微调,以适应类似的预测场景(例如,不同的电池格式、测试环境或测试设备)(图2E)。最后,在之前程序中使用过的实验数据上验证ML预测的准确性(图2F),并在未用于训练或微调的新收集的实验或文献结果上进行测试(图2G)。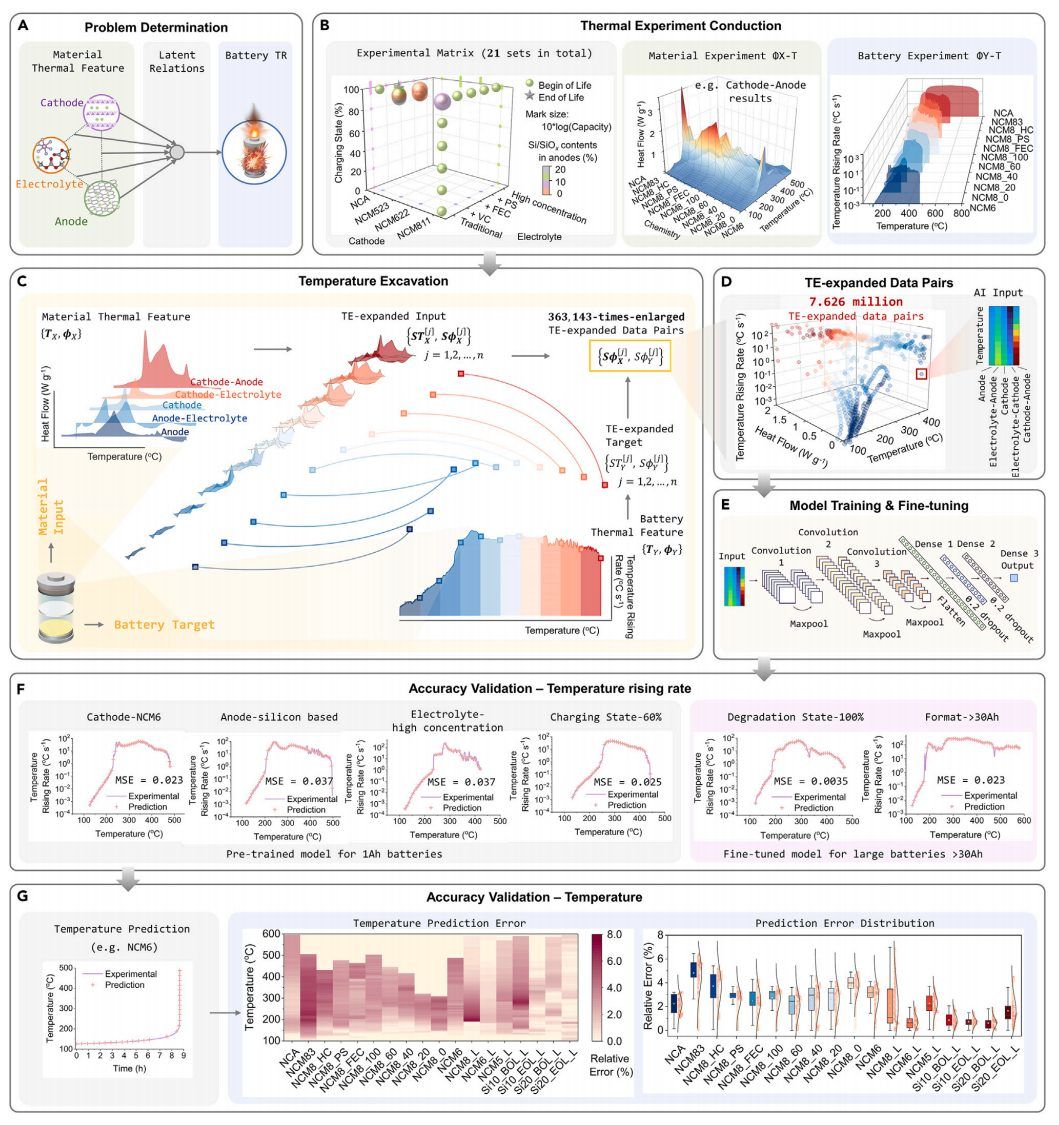 图3 温度挖掘支持的ML预测电池热失控
图3 温度挖掘支持的ML预测电池热失控
TE方法用于解决从材料热特征预测电池热失控(TR)的热化学任务(图3A)。在超过1000℃的宽温度范围内,涉及多种氧化剂,还原剂和自由基的高度相关的热化学反应的存在突出了TR的复杂性。
为了编制一个全面的TR预测实验数据库,作者收集了12种主流商用锂离子化学物质(包括LFP正极,5种不同的层状氧化物正极,石墨和硅基负极,5种不同的电解质)以及3种高级化学物质(锂金属,锂-硫和钠离子化学物质)的数据,包括适用于各种应用(1-74 Ah)的小型和大型电池。该数据库还涵盖了所有正常的电池工作状态(0%-100%充电和降解状态)(图3B)。
图3C展示了TE方法应用于实验材料和电池热特性的过程。输入特征矩阵包括5个维度,表示单个材料及其组合的热流。图3D显示了这些TE扩展数据对的分布。这种分布的分散性表明,电池的TR特性不仅仅取决于材料的加热速率。相反,它们表明了各种电池组件和温度之间复杂的热化学相互作用,这是目前基于其他机制的模型难以捕捉的高度复杂的现象。
经过训练和微调的ML模型在预测电池TR方面显示出显著的准确性和通用性,如图3F和3G所示。ML模型准确地预测了所有实验样品在整个温度范围内的升温速率,包括具有各种正极、负极、电解质、格式、充电状态和降解状态的样品(图3F)。
利用这种精确的速率预测,从而能够确定评估电池安全性的关键指标:初始自热温度(Tinitial)和TR起始温度(Tonset)。通过调整ML模型的预测目标,可以得到最高温度(Tmax)。值得注意的是,这些指标的预测误差在所有实验结果中保持在4%以下。此外,通过积分温度上升速率,准确地捕获了整个TR范围内的温度波动,实现了所有样本的误差小于8%(图3G)。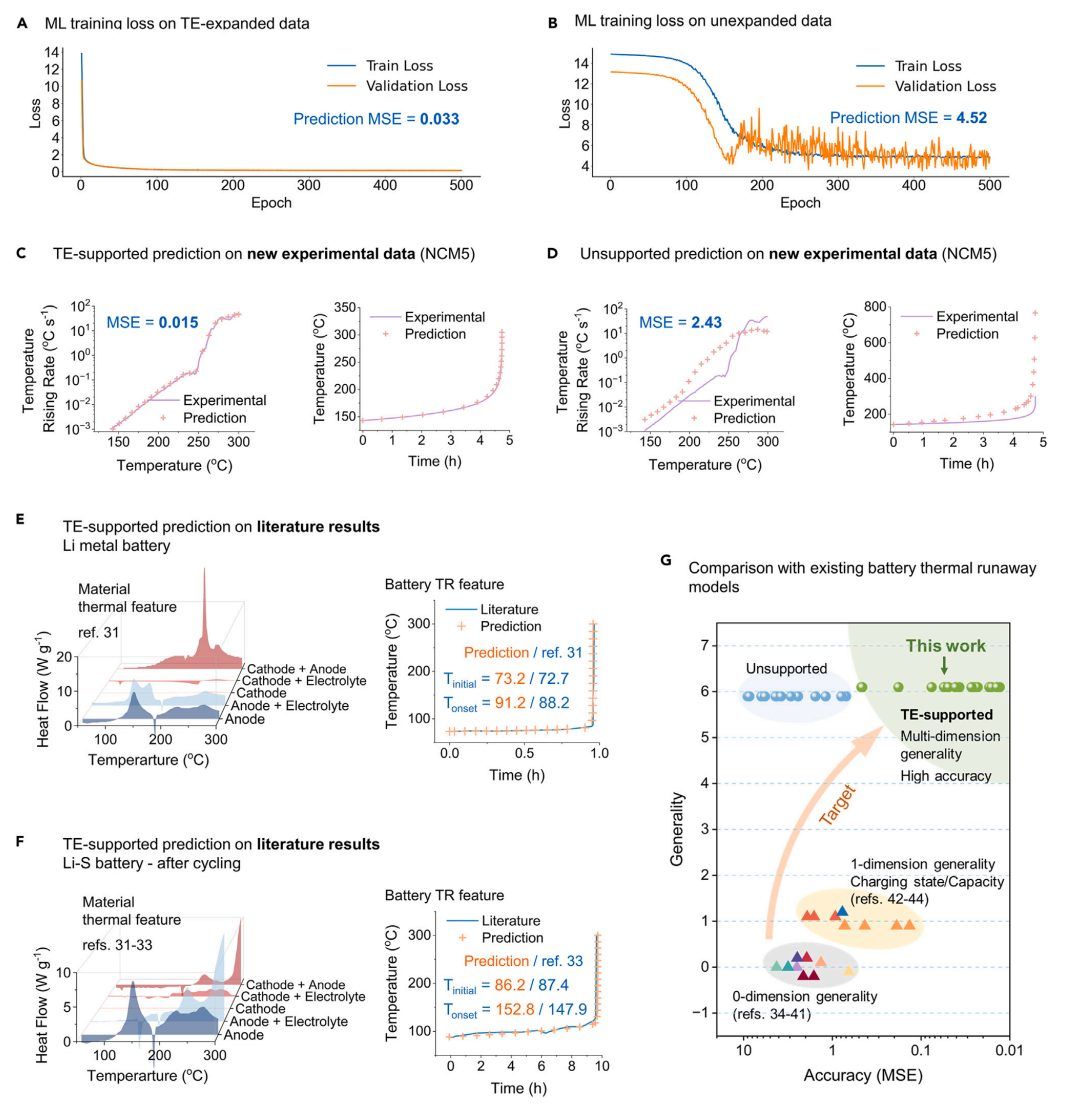 图4 准确和通用预测的热失控模型
图4 准确和通用预测的热失控模型
从图4A和图4B可以明显看出,无温度挖掘支持的ML在训练损失方面出现了明显的波动,这表明由于数据规模有限,存在明显的过拟合问题。值得注意的是,温度挖掘支持的ML在应用于新数据时始终保持较高的预测精度(图4C、D),而不受电极材料、电解质或充电状态变化的影响。
对于文献中报道的传统LFP和更先进的钠离子、锂金属和Li-S电池化学成分,TE支持的模型还提供了基于材料热特性的准确电池TR预测。如图4E、F所示,TE支持的ML准确地捕获了传统LFP和先进电池化学物质的温度随时间的变化。此外,机器学习可以精确识别关键的电池TR指标,包括Tinitial和Tonset,从而基于材料级实验进行可靠的电池级安全评估。
TE扩展的数据对不仅重申而且扩大了实验数据中固有的潜在化学知识,从而在ML模型的准确性、通用性、拟合质量和模型独立性方面取得了显着提高。通过使用TE方法,成功建立了第一个通用的TR模型,在不同的化学物质、电池格式和操作条件下显示出出色的准确性(图4G)。这种机器学习模型大大超越了现有的基于机制的模型,并有效地打破了电池设计中昂贵的“试错”模式。
最重要的是,这一里程碑进展强调了TE方法在帮助ML克服数据稀缺性挑战和满足高复杂性电池热化学任务要求方面的熟练程度。
文献信息
Temperature excavation to boost machine learning battery thermochemical predictions,Joule,2024.https://doi.org/10.1016/j.joule.2024.07.002